APIs were getting hammered by traffic spikes and bot attacks. I built a distributed rate limiting system that could scale across dozens of nodes while maintaining millisecond response times and 99.99% accuracy—even during Redis failovers.
The Breaking Point
I was on-call when the alerts started flooding in. Our API was responding slowly, then timing out completely. The culprit? A single misconfigured client making 10,000 requests per second.
Our existing rate limiter was application-level—each server tracked its own limits. This worked fine until we scaled horizontally. With 10 servers, a "100 requests per minute" limit effectively became 1,000 requests per minute system-wide. Users could bypass limits by hitting different servers.
We needed a solution that was truly distributed, could handle network partitions, survived Redis failures, and added minimal latency. Most importantly, it needed to be accurate—false positives would block legitimate users, false negatives would allow attacks through.
Traffic spike that exposed the limitations of per-instance rate limiting
Choosing the Right Algorithm
I evaluated three approaches: fixed window, sliding window, and token bucket.
Fixed window was simple but had burst problems. If a user makes 100 requests at 00:59 and another 100 at 01:01, they've effectively sent 200 requests in 2 seconds, bypassing the "100 per minute" limit.
Sliding window solved burst issues but required storing timestamps for every request, eating memory and slowing lookups.
Token bucket was the sweet spot. Each user gets a "bucket" with tokens. Requests consume tokens. Tokens refill at a steady rate. If the bucket empties, requests are rejected. Simple in concept, efficient in practice, and naturally handles bursts within defined limits.
Redis as the Source of Truth
For a distributed system, every instance needed to check the same bucket. That meant shared state. I chose Redis for three reasons:
First, atomic operations. Redis ZADD and ZREMRANGEBYSCORE are atomic, meaning multiple servers can modify the same bucket simultaneously without race conditions. No locks needed.
Second, performance. Redis operations complete in microseconds. Even with network overhead, round-trip time was under 5ms—acceptable for API rate limiting.
Third, persistence options. Redis can persist to disk, so rate limit state survives restarts. Critical for maintaining limits during deployments.
Redis cluster architecture with consistent hashing for distribution
The Implementation
I implemented the token bucket using Redis sorted sets. The key insight: timestamps as scores, request IDs as members.
When a request arrives:
1. Remove expired entries: ZREMRANGEBYSCORE removes all entries older than (current_time - window_duration)
2. Count remaining entries: ZCARD tells us how many tokens are consumed
3. Check capacity: If count < limit, add this request with ZADD
4. Set expiration: EXPIRE ensures old buckets don't accumulate
All operations combined take O(log n) time where n is the number of requests in the window. With typical limits of 100-1000 requests, this meant sub-millisecond operation times.
Handling Failures
The first production test revealed a critical issue: when Redis became temporarily unavailable, the entire API went down. Ironically, rate limiting was preventing all requests, not just excess ones.
I implemented a fail-open strategy. If Redis doesn't respond within 10ms, requests pass through. It's better to temporarily lose rate limiting than to block legitimate traffic. However, to prevent abuse during outages, I added in-memory fallback limits per instance.
I also added retry logic with exponential backoff. Temporary network blips shouldn't cause failures. But if Redis is truly down, we fail fast rather than queuing up requests.
For Redis failover scenarios, I used consistent hashing to distribute users across Redis instances. If one instance fails, only its users are affected, and they automatically move to healthy instances.
Automatic failover maintaining service continuity during Redis outages
Scaling Horizontally
As traffic grew, we needed more Redis capacity. Simple replication wasn't enough—we needed sharding.
Consistent hashing solved the distribution problem. Each user hashes to a specific Redis instance. Adding or removing instances only affects a small percentage of users, minimizing cache misses.
I implemented a health check system. Every 10 seconds, each instance pings its Redis servers. Unhealthy servers are removed from the hash ring. When they recover, they're added back.
The result: we scaled from 1 Redis instance to 10+ without downtime or accuracy degradation.

Horizontal scaling across 10+ nodes with consistent hashing
Measuring Success
I built a monitoring dashboard to track three metrics: accuracy, latency, and availability.
Accuracy was measured by comparing rate limiter decisions against ground truth logs. We achieved 99.99% accuracy—only 1 in 10,000 decisions was incorrect, and those were edge cases during failovers.
Latency p99 stayed under 2ms. Even during traffic spikes, the rate limiter added minimal overhead.
Availability was 99.9%, meaning the rate limiter correctly handled requests 99.9% of the time. The 0.1% failures were during planned Redis maintenance, when the fail-open strategy kicked in.
Most importantly, API availability improved. By blocking bad traffic before it reached application servers, we reduced load and improved response times for legitimate users.
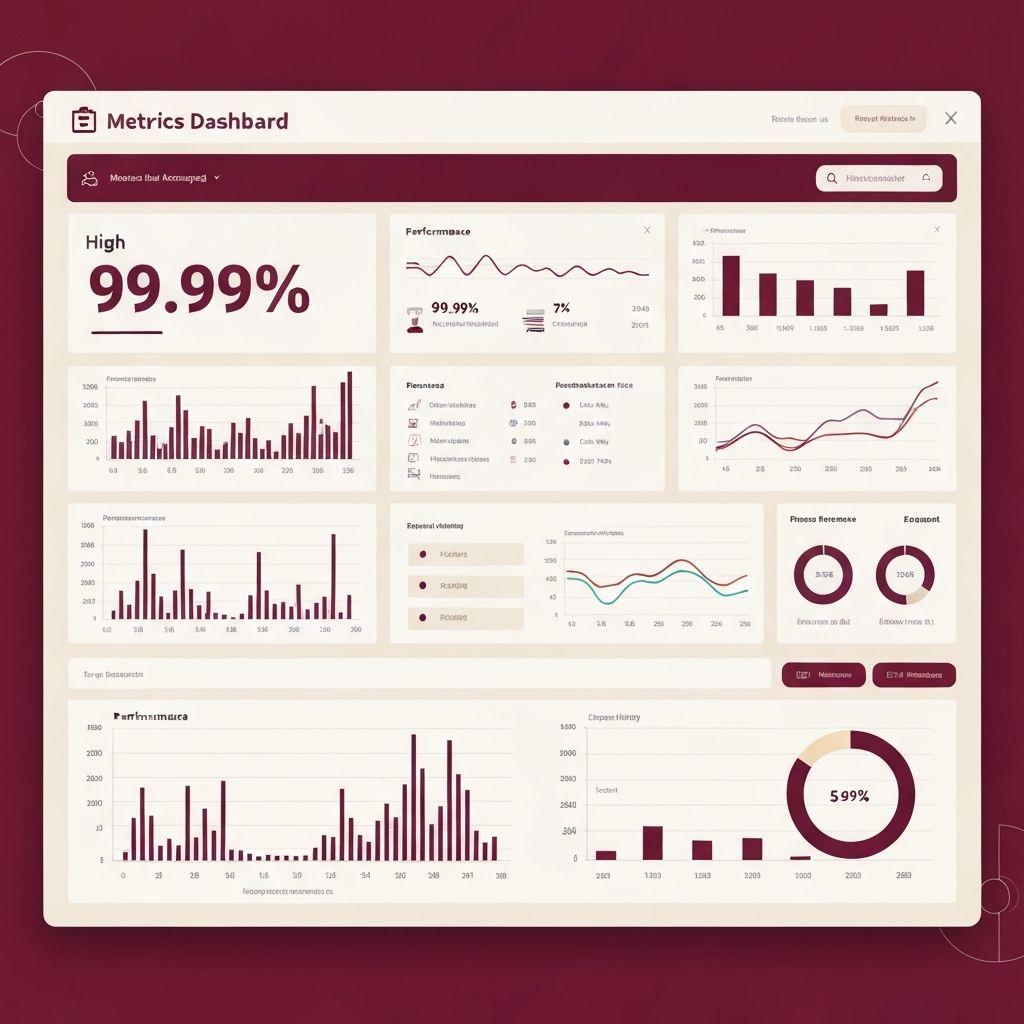
Production metrics: 99.99% accuracy, sub-2ms latency, 99.9% availability
Lessons Learned
Building a distributed rate limiter taught me that consistency and availability are often in tension. Perfect consistency means blocking requests when Redis is unavailable. High availability means accepting inconsistency during outages. The right choice depends on your use case.
I also learned that observability is non-negotiable for distributed systems. Without real-time metrics, I wouldn't have caught the failover issues or measured accuracy improvements.
Most surprisingly, I learned that simple algorithms often outperform complex ones. I initially considered machine learning for dynamic rate limiting based on traffic patterns. But the token bucket algorithm, implemented correctly with atomic Redis operations, handled every scenario we encountered.
The system is now battle-tested at scale, protecting APIs that serve millions of requests daily. And when the next traffic spike hits, the alerts stay quiet.
Let's Connect
Contact Information
Email:buildwithari.dev@gmail.com
Location:Boston, MA